


M1 Traitement de Donnees Biologiques - TP Intro R
From silico.biotoul.fr
Contents |
Prise en main de R et RStudio
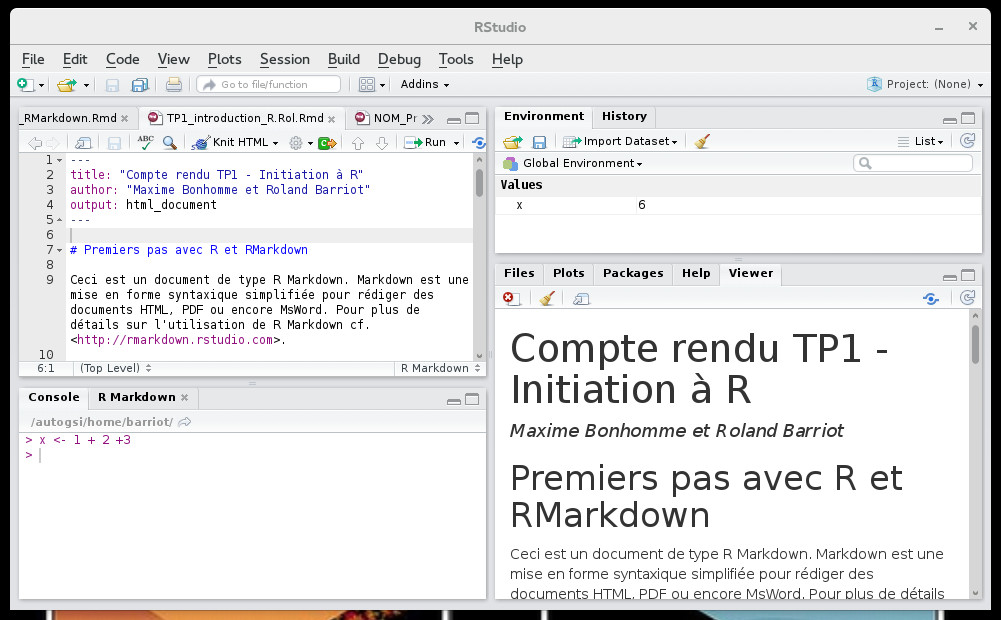
Au cours de ce TP, nous allons utiliser le logiciel R à travers une interface particulière : RStudio. Cette interface permet d'éditer des scripts en R ainsi qu'en langage Markdown que nous allons utiliser pour la rédaction de rapports scientifiques. L'interface se compose en plusieurs parties (cf. capture d'écran ci-dessous) :
- en haut à gauche : édition de fichiers et scripts, et visualisation de certaines données (tableaux)
- en bas à gauche : exécution de code R dans une console
- en haut à droite : les objets et variables chargés en mémoire (Environment)
- en bas à droite : plusieurs onglets : accès aux fichiers, graphiques (Plots), librairies disponibles (Packages), aide (Help), et visualiseur de rapports scientifiques (Viewer)
Créer un répertoire de travail sur le bureau (par exemple TDB-TP1_introduction) et commencez par télécharger le fichier source que vous allez utiliser et compléter pour générer le compte rendu de TP : M1.TDB.TP_introduction_R.Rmd (click droit de la souris -- enregistrer la cible sous...).
Ouvrez le logiciel RStudio et chargez ce fichier puis lancez sa compilation pour voir le rendu comme dans la capture d'écran ci-dessus. Pour cela cliquez sur le bouton Knit HTML ou bien utilisez la combinaison de touches Ctrl + shift + K.
Vous verrez que si la compilation est réussie, un fichier M1.TDB.TP_introcution_R.html va être généré dans le même répertoire que le fichier M1.TDB.TP_introduction_R.Rmd que vous avez téléchargé.
Utilisation et calculs avec du code R
Utilisation de variables
Les variables (ou objets) permettent de stocker des données qui peuvent être :
- une valeur simple de type numérique (numeric), logique (logical), chaîne de caractères (character) ou qualitative (factor).
- une liste (appelée vector).
- un tableau à 2 dimensions, les colonnes pouvant avoir des types différents (data frame). Ce sont les plus utilisés en statistiques.
- un tableau à 2 dimensions, toutes les cases ayant le même type (matrix).
- un tableau à plus de 2 dimension (array).
- une combinaison des précédents (list).
Une variable a un nom (défini par l'utilisateur) qui permet d'accéder à son contenu.
Créer une variable appelée x qui stocke le résultat du calcul précédent 1 + 2 + 3. L'affectation d'une valeur à une variable se fait avec <- ou le signe = comme suit dans la console :
x = 1 + 2 + 3
Vous devriez voir s'afficher x dans l'environnement en haut à droite comme sur la capture d'écran précédente.
Pour afficher le contenu d'une variable, il suffit de taper son nom (dans la console en bas à gauche) :
x
Rajoutez ces commandes à votre compte rendu de TP (script en haut à gauche) et assurez-vous que cela fonctionne (en recompilant le fichier).
Essayez avec les autres types de variables simples. Par exemple :
texte = "Phrase qu'il faut mettre entre guillemets." logique = TRUE faux = FALSE # ce qui est après un # correspond à du commentaire et n'est pas interprété comme du code x = x * 2 # on multiplie x de toute à l'heure par 2 y = x**2 # y prend la valeur de x au carré (puissance 2)
Les valeurs logiques peuvent être le résultats de tests :
x < 10 # strictement inférieur à 10 ? x <= 11 # inférieur ou égal x == 12 # test d'égalité x >= 13 x > 0 x != 0 # test si x est différent de 0 ! FALSE # inverse une valeur logique
Ajoutez ces parties à votre compte rendu.
Vecteurs
Créez un vecteur x contenant les valeurs 2,3,5,8,4,6 rassemblées avec la fonction c() :
x = c(2,3,5,8,4,6) x
Calculez sa longueur avec la fonction length() :
length(x)
Accès à certains éléments : Affichez la deuxième valeur de x. Pour cela, on utilise les crochets :
x[2]
Pour accéder à plusieurs éléments, on utilise un vecteur contenant les positions :
x[ c(2,4,1) ]
Si les positions se suivent, on peut utiliser les :
2:4 x[2:4]
ou dans l'ordre inverse :
4:2 x[4:2]
On peut aussi accéder à tous les éléments sauf certains :
x[ -2 ] # tous, sauf le 2ème x[ -2:-3 ] # tous, sauf le 2ème et le 3ème
Exploration suivant un critère: vrai/faux, indices, ou valeurs
x>4 which( x>4 ) x[ x>4 ]
Effectuer une opération sur chaque élément :
x 1 / x # en arrondissant 2 chiffres après la virgule) round(1/x, 2) x + 1 x * 2
Ajoutez ces parties à votre compte rendu.
Fonctions
R charge certaines librairies au démarrage selon son installation et sa configuration. Les librairies mettent à disposition des fonctions qui peuvent être très simples, jusqu'à très très compliquées.
Essayez les suivantes sur votre vecteur x. Et notez dans votre compte rendu ce qu'elles permettent de faire.
- summary(x)
- min
- max
- median
- mean
- var
- sd
Afin de mieux comprendre ce qu'elles font et quels sont les paramètres que l'on peut leur passer, utilisez l'aide :
help(median)
ou plus simplement :
?mean
Quand on ne connaît pas exactement le nom, on peut faire une recherche par mot :
??mean
Lecture et écriture de fichiers contenant des données
Les fonctions permettant de lire et d'écrire des données dans des fichiers sont :
- read.table
- read.csv et read.csv2
- read.delim et read.delim2
- write.table
- write.csv et write.csv2
- write.delim et write.delim2
Ce sont à peu près les mêmes fonctions mais elles prennent des paramètres par défaut légèrement différents. Commencez par consulter leur documentation.
Téléchargez et sauvegardez le fichier suivant dans le même répertoire que toute à l'heure. (click droit puis enregistrer la cible sous...) : croissance_plantes.txt
Afin de visualiser son contenu, vous pouvez l'ouvrir d'abord avec un éditeur de texte (Textpad, Notepad++ ou geany), ou un tableur LibreOffice Calc (ou Ms Excel).
Remarque : il faut en général éviter de mettre des espaces dans les noms de variables, ainsi que des accents
Ensuite, avant de charger les données, il faut dire à R de se placer dans votre répertoire de travail. Sinon, il ne trouvera pas le fichier et vous aurez une erreur à la suite de la commande read.table. Pour cela, cliquez sur le menu Session puis Set Working Directory > To Source File Location. Il y aussi la possibilité de sélectionner le répertoire avec l'option Choose Directory... ou la combinaison de touches Ctrl + shift + H.
Après cela, essayez la fonction read.table sur le fichier croissance_plantes.txt que vous avez récupéré. Il vous faudra utiliser les paramètres sep et header pour désigner le séparateur de colonnes (tabulation notée \t) ainsi que le fait que la première ligne correspond aux noms des colonnes (header=TRUE):
read.table("croissance_plantes.txt", sep="\t",header=TRUE)
Avec la commande ci-dessus, si le fichier est dans le répertoire de travail, il va être chargé. Comme il n'est pas affecté à une variable, il va être affiché. Pour le garder en mémoire dans une variable, il faut le spécifier :
croissance = read.table("croissance_plantes.txt", sep="\t",header=TRUE)
Après cela, la variable croissance doit apparaître dans l'environnement. Si vous cliquez dessus, son contenu doit être ouvert dans un nouvel onglet. Vous verrez aussi dans la console la commande qui a été exécutée pour l'ouvrir : View(croissance).
Ce type de tableau est appelé data.frame en R. Chaque colonne a un type. C'est ce qui est le plus utilisé en statistiques avec les individus en lignes et les variables en colonnes. Essayez la fonction summary ainsi que la fonction dim.
Comme pour un vecteur, on peut afficher le contenu entier, ou accéder à certaines lignes et/ou colonnes :
croissance croissance[1 , ] # ligne 1 croissance[ , 1] # colonne 1 croissance[1, 1] # première case croissance$poids # colonne qui s'appelle poids (la première) croissance[ , 'poids'] # encore une autre manière d'y accéder
Pour obtenir le nom des colonnes :
names(croissance)
Il est aussi possible d'utiliser colnames et rownames.
Pour y accéder sans avoir à chaque fois à mettre le nom croissance, on utilise attach :
attach(croissance) poids
Pour récupérer une partie des données, on peut faire comme précédemment avec un vecteur. Par exemple pour ne récupérer que les lignes correspondant à des données d'origine des pyrénées :
origine_geo == 'pyr' # test pour obtenir VRAI/FAUX which(origine_geo == 'pyr') # test pour obtenir les numéros des lignes # et ensuite croissance[ origine_geo == 'pyr' , 1:2 ] # ou bien croissance[ which(origine_geo == 'pyr') , 1:2 ] # pour stocker le résultats dans une autre variable pyr = croissance[ origine_geo == 'pyr' , 1:2 ]
Ensuite, sauvegardez cette partie des données avec la fonction write.table et ouvrez le résultat avec Textpad ou LibreOffice :
write.table(pyr, "croissance_plantes_pyr.txt", quote=F, col.names=T, row.names=F, sep="\t")
Vous remarquez au passage que l'on peut écrire TRUE avec seulement T, (et FALSE avec F).
Fonctions graphiques
Pour commencer, un camembert avec le nombre d'individus par origine (variable qualitative) :
summary(origine_geo) # les effectifs pie( summary(origine_geo) ) # le camembert pie (summary(origine_geo), main="origine géographique des plantes") # avec un titre
Un histogramme (variable quantitative):
hist(taille, xlim=c(40,90), xlab="taille (cm)", ylab="effectif", freq=T, main="histogramme de la taille des plantes", col="orange")
Une boite à moustaches (variable quantitative):
boxplot(taille, main="boxplot de la taille des plantes", ylab="taille")
Plusieurs boites à moustaches (une variable quantitative en fonction des modalités d'une variable qualitative):
plot(origine_geo, taille, las=3, main="boxplot de la taille des plantes en fonction de l'origine géographique") stripchart(taille~origine_geo,las=1)
Un graphique à 2 dimensions ou nuage de points ( 2 variables quantitatives mesurées sur les mêmes individus) :
plot( taille, poids)
Affichage de plusieurs graphiques dans la même fenêtre :
par(mfrow=c(2,2)) # 2 en lignes et 2 en colonnes hist(taille,xlim=c(40,90),xlab="taille (cm)",ylab="effectif",freq=T,main="histogramme de la taille des plantes",col="orange") boxplot(taille,main="boxplot de la taille des plantes",ylab="taille") plot(taille~origine_geo,las=3) stripchart(taille~origine_geo,las=1)
Ouverture d'une nouvelle fenêtre graphique (à ne pas inclure dans le fichier RMardown car il sert à générer un fichier HTML qui ne peut pas ouvrir de fenêtre graphique) :
x11()
Sauvegarde et/ou exportation des graphiques. Dans l'onglet Plots, au choix dans le menu Export :
- Save as Image... : différents format disponibles (PNG, JPEG, TIFF, SVG, ...)
- Save as PDF...
- Copy to Clipboard... : copie en mémoire (presse papier). Essayez de le coller par exemple dans MsWord, Powerpoint ou LibreOffice.
Ajoutez tout cela au compte rendu de TP avant de l'envoyer à votre enseignant par mail (bonhomme@lrsv.ups-tlse.fr ou barriot@biotoul.fr). Le compte rendu est à envoyer avant de commencer le TP2. Envoyez les 2 fichiers (.Rmd et .html). Envoyez-vous aussi le mail en copie pour pouvoir vérifier que tout est bien passé. Mettez un titre tel que "Compte rendu TP1 TDB de -et votre Nom et Prénom-".
Liens
- Site de R : http://www.r-project.org et sites miroirs (dont ceux en France) pour télécharger le logiciel et les librairies : https://cran.r-project.org/mirrors.html
- RStudio : https://www.rstudio.com
- Utilisation de R depuis un navigateur : http://www.r-fiddle.org
Chargement des données avec l'adresse des fichiers
croissance = read.table("http://silico.biotoul.fr/site/images/9/97/Croissance_plantes.txt", sep="\t",header=TRUE)