


L2 AADB TP BD Resistance
From silico.biotoul.fr
m (→Accès au données réparties sur plusieurs tables) |
m (→Accès au données réparties sur plusieurs tables) |
||
| Line 107: | Line 107: | ||
La conception du schéma de la base nous a amenés à morceler les données et à les répartir sur plusieurs tables. Il est donc essentiel de pouvoir faire le lien entre ces informations. Pour cela, vous allez exploiter les ''clés étrangères''. | La conception du schéma de la base nous a amenés à morceler les données et à les répartir sur plusieurs tables. Il est donc essentiel de pouvoir faire le lien entre ces informations. Pour cela, vous allez exploiter les ''clés étrangères''. | ||
| + | |||
| + | === Le SELECT FROM === | ||
Dans un premier temps, ajoutez un nouvel organisme pathogène à la table ''organisme_mo'' avec les valeurs suivantes : | Dans un premier temps, ajoutez un nouvel organisme pathogène à la table ''organisme_mo'' avec les valeurs suivantes : | ||
| Line 121: | Line 123: | ||
Vous constaterez que chaque ligne de la première table est associée à chaque ligne de la 2ème. Il s'agit du produit de 2 tables. | Vous constaterez que chaque ligne de la première table est associée à chaque ligne de la 2ème. Il s'agit du produit de 2 tables. | ||
| + | |||
| + | === La clause WHERE === | ||
Pour n'obtenir que les lignes pour lesquelles le pathogène de la ''manip'' correspond au pathogène de la table ''organisme_mo'', il faut ajouter la contrainte que ces attributs aient même valeur : | Pour n'obtenir que les lignes pour lesquelles le pathogène de la ''manip'' correspond au pathogène de la table ''organisme_mo'', il faut ajouter la contrainte que ces attributs aient même valeur : | ||
| Line 129: | Line 133: | ||
</source> | </source> | ||
| + | === La jointure === | ||
Cela s'appelle faire une '''jointure''' entre ces 2 tables. Une écriture plus lisible de la même requête est la suivante : | Cela s'appelle faire une '''jointure''' entre ces 2 tables. Une écriture plus lisible de la même requête est la suivante : | ||
| Line 146: | Line 151: | ||
[[Image:BD_Resistance_Spreadsheet_Selected_Columns.png]] | [[Image:BD_Resistance_Spreadsheet_Selected_Columns.png]] | ||
| + | === Les vues === | ||
Il s'agit d'une requête assez lourde du fait des nombreuses jointures entre les différentes tables. Néanmoins, sur une petite base de données comme celle-ci, cela peut simplifier l'écriture de requêtes, notamment celles qui suivent. | Il s'agit d'une requête assez lourde du fait des nombreuses jointures entre les différentes tables. Néanmoins, sur une petite base de données comme celle-ci, cela peut simplifier l'écriture de requêtes, notamment celles qui suivent. | ||
| Line 170: | Line 176: | ||
* Afficher les plantes mortes qui ont leurs cotylédons complètement jaunis (avec la vue ''plantes''). | * Afficher les plantes mortes qui ont leurs cotylédons complètement jaunis (avec la vue ''plantes''). | ||
| + | |||
| + | === Le tri : ORDER BY === | ||
Il est possible de trier les résultats sur une ou plusieurs colonnes avec l'instruction <tt>ORDER BY</tt> suivie des n° ou noms de colonnes du résultat, et ceci par ordre croissant (comportement par défaut) ou décroissant en indiquant après chaque colonne ASC (pour le tri par ordre croissant) ou DESC (pour l'ordre décroissant). Exemple : | Il est possible de trier les résultats sur une ou plusieurs colonnes avec l'instruction <tt>ORDER BY</tt> suivie des n° ou noms de colonnes du résultat, et ceci par ordre croissant (comportement par défaut) ou décroissant en indiquant après chaque colonne ASC (pour le tri par ordre croissant) ou DESC (pour l'ordre décroissant). Exemple : | ||
| Line 185: | Line 193: | ||
* Afficher le nombre de mesures effectuées à 21 jours. | * Afficher le nombre de mesures effectuées à 21 jours. | ||
| + | |||
| + | === L'agrégation : GROUP BY === | ||
* Il est possible d'''agréger'' des lignes ayant même valeur. Par exemple, on peut regrouper les lignes par accession afin de compter les lignes pour chacun d'entre eux. Ceci se fait avec l'instruction <tt>GROUP BY</tt> suivie des noms de colonnes pour lesquelles les lignes ayant même valeur vont être agrégées. Exemple, pour obtenir le nombre d'accession par pays : | * Il est possible d'''agréger'' des lignes ayant même valeur. Par exemple, on peut regrouper les lignes par accession afin de compter les lignes pour chacun d'entre eux. Ceci se fait avec l'instruction <tt>GROUP BY</tt> suivie des noms de colonnes pour lesquelles les lignes ayant même valeur vont être agrégées. Exemple, pour obtenir le nombre d'accession par pays : | ||
| Line 202: | Line 212: | ||
* Afficher la moyenne du pourcentage de brunissement par boite. | * Afficher la moyenne du pourcentage de brunissement par boite. | ||
| - | Quelques fois, on souhaite filtrer les résultats après regroupement plutôt qu'avant, par exemple sur le résultat du AVG+GROUP BY plutôt que sur les données contenues dans la table de départ. Dans ce cas, il n'est pas possible de filtrer avec un WHERE habituel . | + | === Le filtrage après regroupement : GROUP BY + HAVING === |
| + | |||
| + | Quelques fois, on souhaite filtrer les résultats après regroupement plutôt qu'avant, par exemple sur le résultat du AVG+GROUP BY plutôt que sur les données contenues dans la table de départ. Dans ce cas, il n'est pas possible de filtrer avec un WHERE habituel ; il faut utiliser l'instruction HAVING qui applique le filtre après le regroupement du GROUP BY. Par exemple, pour afficher les pays pour lesquels on dispose d'au moins 20 accessions : | ||
| + | <source lang='SQL'> | ||
| + | SELECT pays, COUNT(*) | ||
| + | FROM organisme_pl | ||
| + | GROUP BY pays | ||
| + | HAVING COUNT(*)>=20 | ||
| + | </source> | ||
* Afficher la moyenne du pourcentage de brunissement par boite des plantes résistantes uniquement. | * Afficher la moyenne du pourcentage de brunissement par boite des plantes résistantes uniquement. | ||
| Line 210: | Line 228: | ||
* Le nombre de racines secondaires par accession résistant (dont le pourcentage de brunissement est inférieur à 100%). | * Le nombre de racines secondaires par accession résistant (dont le pourcentage de brunissement est inférieur à 100%). | ||
| - | + | === Synthèse des éléments d'une requête === | |
<source lang='SQL'> | <source lang='SQL'> | ||
SELECT -- choix des colonnes. ex: hapmap_id, num_boite AS plante, count(*) | SELECT -- choix des colonnes. ex: hapmap_id, num_boite AS plante, count(*) | ||
Revision as of 10:25, 27 March 2012
Afin de créer la base de données qui s'appellera resistance, connectez vous sur le site http://localhost/phpMyAdmin
Il s'agit d'un serveur Web local (installé sur votre ordinateur). Le programme faisant office de serveur Web s'appelle Apache. Des pages Web dynamiques fournissent une interface Web de gestion de bases de données (phpMyAdmin) pour un serveur de bases de données MySQL.
Ces programmes sont open sources et/ou gratuits et peuvent être installés sur Windows, Linux ou MasOS. Il existe des projets les rassemblant et qui permettent donc une installation rapide pour les néophytes : http://www.wampserver.com pour Windows par exemple.

Contents |
Création de la base de données
Pour commencer, il faut créer une nouvelle base de données. Pour cela, cliquez sur l'onglet Bases de données. Vous avez alors la possibilité de nommer cette nouvelle base et de cliquez sur le bouton Créer. Cette nouvelle base devrait ensuite s'afficher sur la gauche de la page avec les autres bases existantes (information_schema, mysql et test normalement).
Vous pouvez alors cliquer sur cette nouvelle base pour la sélectionner. Il devrait s'afficher une page vous proposant de créer une nouvelle table.
Si vous désirez supprimer une base, vous pouvez après l'avoir sélectionnée, aller dans l'onglet Opérations, et cliquez sur Supprimer la base de données.
Création de tables
Pour cela, il faut sélectionner une base de données. Puis, dans l'onglet Structure, indiquez le nom de la table ainsi que le nombre de colonnes. D'où l'importance de déterminer à l'avance le schéma de la base de données. Néanmoins, la plupart des systèmes de gestion de bases de données (SGBD) actuels autorisent la modification de la structure de la base (ajout, suppression, renommage de colonnes et autres).
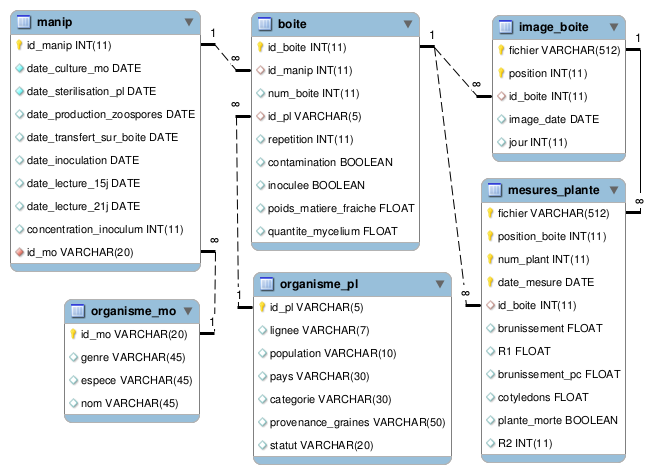
Il va vous falloir créer les tables que vous avez déterminer pour l'étude de la résistance des plantes au microorganisme. Exemple avec la table recueillant les informations sur les lignées des plantes : organisme_pl, cette table a 7 colonnes qui sont les suivantes :
- hapmap_id
- lignee
- population
- pays
- categorie
- provenance_graines
- statut
Cette table a été obtenue à partir du projet http://www.medicagohapmap.org/. Sur ce site, les données contenues dans la table sont sur la page http://www.medicagohapmap.org/public_germ_db/germplasm_db_report.php?1
Pour créer cette table, après avoir renseigner son nom et qu'elle comporte 7 colonnes, une fenêtre apparaît dans laquelle il faut donner le nom de chaque colonne ainsi que son type.
Il y a différents types disponibles. Les principaux sont les suivant :
- nombre entier : INT
- nombre réel : FLOAT
- texte (sur une seule ligne = chaine de caractères de longueur variable) : VARCHAR(n) avec n la longueur maximale autorisée.
- texte (sur plusieurs lignes) : TEXT
- date (attention au format AAAA/MM/JJ) : DATE
- date et heure : DATETIME
- etc.
Déterminez le type des attributs et créez la table organisme_pl.
Une fois la table créée, il est encore possible de modifier sa structure. Pour cela, si besoin, il faut cliquer sur la table, puis sur l'onglet structure. Sut cette page, vous pouvez modifier le type d'un attribut, ainsi qu'ajouter ou supprimer des colonnes.
Edition manuelle des données
Une fois que vous aurez créé au moins une table, cliquez sur la page correspondante et créez une nouvelle ligne à partir de l'onglet Insérer.
Après l'insertion, en sélectionnant de nouveau cette table, une partie des lignes qu'elle contient est affichée. Vous devriez donc voir apparaître la ligne que vous venez de créer. Ceci correspond en fait au résultat de la requête de consultation qui s'affiche en début de page (SELECT * FROM ...) ; nous y reviendrons un peu plus tard.
Remarquez qu'il est également possible de modifier les lignes (appelés tuples dans le jargon des bases de données) à partir des liens Modifier, Editer en place, Effacer.
Sauvegarde et restauration d'une base de données
La sauvegarde (appelée souvent dump) se fait dans l'onglet Exporter. Selon que vous êtes sur la page de la base ou sur la page d'une table, l'export se fera soit de la base complète soit de la table sélectionnée.
L'export permet de sauvegarder une image de la structure et des données de la base, ce qui permet de la restaurer sur un autre serveur de base de données (ou le même).
Essayez donc en cliquant sur l'onglet Exporter avec les options par défaut. Enregistrez puis/ou visualisez le fichier avec un éditeur de texte. Il s'agit du langage SQL et des commandes permettant la création de(s) table(s) puis l'insertion des données qu'elles contiennent. Les principales commandes sont donc :
- CREATE TABLE nom_de_la_table (nom_colonne type_colonne, ...
- INSERT INTO nom_de_la_table (noms des colonnes concernées) VALUES (valeurs pour ces colonnes)
Maintenant que vous disposez d'une sauvegarde, vous pouvez supprimer votre base de données. Pour la suite du TP, vous allez travailler sur un dump contenant à la fois la structure (création des tables) et un sous-ensemble des données correspondant aux manips 12, 13 et 14.
{kind=link}
Vous allez donc restaurer cette image en cliquant sur l'onglet Importer et en fournissant le fichier correspondant à la sauvegarde.
Après avoir restaurer cette image, allez sur la page de la base resistance. Combien y a-t-il de lignes dans chacune des table ?
Explorez les données et déterminez quel accession est le moins sensible (sur la moyenne du brunissement des plantes et des répétitions biologiques).
Requêtes de consultation
Nous allons maintenant appréhender le langage SQL permettant d'interroger efficacement le contenu d'une ou plusieurs table. A peu près n'importe quelle requête de consultation se fait à partir d'une seule commande : SELECT
Pour simplifier, une requête SELECT se décompose en 3 parties :
SELECT noms des colonnes à afficher FROM noms des tables concernées WHERE conditions pour afficher une ligne
Exemple : pour afficher la totalité du contenu de la table organisme_pl
SELECT * FROM organisme_pl
Essayez cette commande à partir de l'onglet SQL.
Ainsi, pour n'afficher que les accessions venant d'un pays, il suffit de rajouter ce filtre/cette contrainte :
SELECT * FROM organisme_pl WHERE pays='Greece'
Combien d'accessions proviennent de Chypre ? de France et du Maroc ?
La partie WHERE permet de spécifier un filtre ou une contrainte pour qu'une ligne soit affichée. Cela correspond en fait a une formule logique qui doit s'interpréter à vrai ou faux ; vrai implique que la ligne sera affichée.
Affichez les fichier, id_boite, num_plant et R1 des plantes dont le brunissement est à 100%. Combien y en a-t-il ?
Afin d'y voir un peu plus clair, on peut trier par identifiant de boite puis par n° de plante pour voir si on a beaucoup de plantes d'une même boite. Pour cela, on rajoute à la requête précédente : ORDER BY id_boite, num_plant
Accès au données réparties sur plusieurs tables
La conception du schéma de la base nous a amenés à morceler les données et à les répartir sur plusieurs tables. Il est donc essentiel de pouvoir faire le lien entre ces informations. Pour cela, vous allez exploiter les clés étrangères.
Le SELECT FROM
Dans un premier temps, ajoutez un nouvel organisme pathogène à la table organisme_mo avec les valeurs suivantes :
- id : PP_INRA-310_V1
- genre : Phytophthora
- espèce : parasitica
- nom : P. parasitica
Ensuite, effectuez la requête suivante :
SELECT * FROM manip, organisme_mo
Vous constaterez que chaque ligne de la première table est associée à chaque ligne de la 2ème. Il s'agit du produit de 2 tables.
La clause WHERE
Pour n'obtenir que les lignes pour lesquelles le pathogène de la manip correspond au pathogène de la table organisme_mo, il faut ajouter la contrainte que ces attributs aient même valeur :
SELECT * FROM manip, organisme_mo WHERE manip.id_mo=organisme_mo.id
La jointure
Cela s'appelle faire une jointure entre ces 2 tables. Une écriture plus lisible de la même requête est la suivante :
SELECT * FROM manip JOIN organisme_mo ON (manip.id_mo=organisme_mo.id)
Essayez d'écrire les requêtes permettant d'obtenir les informations suivantes :
- Images et mesures associées à un accession, HM020 par exemple. (hapmap_id, repetition, num_boite, incoculee, et toutes mes mesures).
- Distribution du poids des plantes résistantes inoculées.
- Générer le fichier de départ.
Les vues
Il s'agit d'une requête assez lourde du fait des nombreuses jointures entre les différentes tables. Néanmoins, sur une petite base de données comme celle-ci, cela peut simplifier l'écriture de requêtes, notamment celles qui suivent.
Comme le résultat d'une requête est... une table, il est possible de sauvegarder ce résultat dans une table virtuelle que l'on appelle vue (view en anglais), puis par la suite, d'effectuer des requêtes sur cette vue.
Vous trouverez la réponse à la question précédente à la fin du dump que vous avez récupéré :
CREATE VIEW plantes AS SELECT ...
Il est ainsi possible de faire des requêtes sur la vue (table virtuelle) plantes. Exemple, pour afficher les plantes contaminées :
SELECT * FROM plantes WHERE contaminee=1
Remarque : l'utilisation d'une telle vue n'est pas indiquée dans le cas où les tables contiennent chacune des milliers de lignes.
- Afficher les plantes mortes (accession, n° répétition, n° boite, n° plante, inoculée, contaminée) qui ont leurs cotylédons complètement jaunis (sans la vue plantes).
- Afficher les plantes mortes qui ont leurs cotylédons complètement jaunis (avec la vue plantes).
Le tri : ORDER BY
Il est possible de trier les résultats sur une ou plusieurs colonnes avec l'instruction ORDER BY suivie des n° ou noms de colonnes du résultat, et ceci par ordre croissant (comportement par défaut) ou décroissant en indiquant après chaque colonne ASC (pour le tri par ordre croissant) ou DESC (pour l'ordre décroissant). Exemple :
SELECT * FROM organisme_pl WHERE statut != 'In Progress' ORDER BY pays, provenance_graines DESC, statut
Refaites la requête précédente en affichant d'abord les boites contaminées et en triant par accession et répétition croissantes.
- Afficher le nombre de mesures effectuées. Pour cela, vous aurez besoin de la fonction count : SELECT COUNT(*) FROM ...
- Afficher le nombre de mesures effectuées à 21 jours.
L'agrégation : GROUP BY
- Il est possible d'agréger des lignes ayant même valeur. Par exemple, on peut regrouper les lignes par accession afin de compter les lignes pour chacun d'entre eux. Ceci se fait avec l'instruction GROUP BY suivie des noms de colonnes pour lesquelles les lignes ayant même valeur vont être agrégées. Exemple, pour obtenir le nombre d'accession par pays :
SELECT pays, COUNT(*) FROM organisme_pl GROUP BY pays
Remarque : la recette qui marche presque toujours pour ce type de requêtes est de faire le SELECT sur les colonnes qui nous intéressent (ici pays) en y ajoutant la fonction qui nous intéresse (ici COUNT) et de faire le regroupement sur les colonnes sélectionnées (ici pays). Les autres fonctions disponibles qui "agrègent" des lignes sont la somme (SUM), la moyenne (AVG), le minimum (MIN), le maximum (MAX), ...
- Effectuer la même requête que dans l'exemple en triant par ordre décroissant le nombre d'accession et en triant les noms des pays par ordre alphabétique.
- Afficher le nombre de boites par accession.
- Afficher la moyenne du pourcentage de brunissement par boite.
Le filtrage après regroupement : GROUP BY + HAVING
Quelques fois, on souhaite filtrer les résultats après regroupement plutôt qu'avant, par exemple sur le résultat du AVG+GROUP BY plutôt que sur les données contenues dans la table de départ. Dans ce cas, il n'est pas possible de filtrer avec un WHERE habituel ; il faut utiliser l'instruction HAVING qui applique le filtre après le regroupement du GROUP BY. Par exemple, pour afficher les pays pour lesquels on dispose d'au moins 20 accessions :
SELECT pays, COUNT(*) FROM organisme_pl GROUP BY pays HAVING COUNT(*)>=20
- Afficher la moyenne du pourcentage de brunissement par boite des plantes résistantes uniquement.
- Afficher les informations sur la boite, et le brunissement moyen à 15 et 21 jours en triant sur le pourcentage de brunissement, en n'affichant que les boites inoculées non contaminées.
- Le nombre de racines secondaires par accession résistant (dont le pourcentage de brunissement est inférieur à 100%).
Synthèse des éléments d'une requête
SELECT -- choix des colonnes. ex: hapmap_id, num_boite AS plante, count(*) FROM -- choix des tables. ex: organisme_pl p JOIN boite b ON (p.hapmap_id=b.id_pl) WHERE -- filtre éventuel sur les lignes à afficher. ex: b.inoculee=1 AND b.contaminee=0 GROUP BY -- regroupement éventuel de lignes. ex: hapmap_id, num_boite HAVING -- filtre sur les valeurs des lignes regroupées ex: AVG(poids_matiere_fraiche)>1 ORDER BY -- tri des résultats ex: 3 DESC