


M1 MABS BBS Data Mining k nearest neighbors
From silico.biotoul.fr
k nearest neighbors
Algorithme des k plus proches voisins : à partir d'un k donné, d'un jeu d'entrainement et d'un exemple T à classer, il s'agit de déterminer la distance entre T et chacun des exemples du jeu d'entrainement, d'en retenir les k dont la distance est la plus faible et d'attribuer la classe majoritaire parmi ces k exemples à T.
Vous allez réaliser un tel classificateur sous la forme d'un script python prenant en entrée un fichier correspondant au jeu d'apprentissage (format Orange), un ficher avec des exemples à classer (texte tabulé, la première ligne correspondant aux noms des colonnes) et le paramètre k (prenant comme valeur 5 par défaut).
Il vous faudra donc définir une fonction pour calculer la distance entre 2 exemples. Pour ce script, on utilisera la formule de la moyenne suivante : 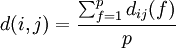 avec p le nombre d'attributs et dij(f) la distance entre i et j pour l'attribut f. Vous utiliserez la distance de manhattan pour les valeurs numériques et le coefficient simple d'appariement pour les valeurs nominales.
avec p le nombre d'attributs et dij(f) la distance entre i et j pour l'attribut f. Vous utiliserez la distance de manhattan pour les valeurs numériques et le coefficient simple d'appariement pour les valeurs nominales.
Afin de ne pas donner plus de poids aux attributs de types numériques ayant une plus grande plage de valeurs, il faudra normaliser ces attributs. Vous utiliserez un z-score du type 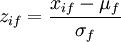 avec μf la moyenne des valeurs de l'attribut f et σf son écart-type.
avec μf la moyenne des valeurs de l'attribut f et σf son écart-type.
Pour effectuer cette normalisation, il faudra donc calculer et mémoriser la moyenne et l'écart-type des variables continues. Dans un soucis d'efficacité, on minimisera le nombre de fois où le jeu d'entrainement est parcouru. Pour cela, vous utiliserez la méthode décrite dans ce tutoriel pour calculer la moyenne et l'écart-type en une seule fois.
Le début du script vous est donné avec les parties à compléter :
#!/usr/bin/python import argparse import csv import numpy import sys import math # SCRIPT PARAMETERS parser = argparse.ArgumentParser(description='k-nn classifier.') parser.add_argument('--training', required=True, help='File in Orange format containing training examples.') parser.add_argument('--sample', required=True, help='File containing new objects to be classified.') parser.add_argument('--k', required=False, default=5, help='Number of nearest neighbor to consider (default 5)') opt = vars(parser.parse_args()) # GLOBAL VARIABLES targetClass = '' attributeClass = {} attributeInfo = {} # SCAN TRAINING SET TO DETERMINE INFO (used to compute mean and standard deviation) with open(opt['training']) as f: reader = csv.DictReader(f, delimiter='\t') # LOAD ATTRIBUTE TYPES (continuous, discrete, ignore) attributeClass = reader.next() #for attribute in attributeClass: # if attributeClass[attribute]=='continuous': # # TO DO: initialization # DETERMINE TARGET CLASS classLine = reader.next() for i in attributeClass: if classLine[i]=='class': targetClass = i # BUILD UP MEAN AND STANDARD DEVIATION IN ONE PASS for row in reader: # # TO DO # COMPUTE MEAN AND STANDARD DEVIATION FOR NUMERIC ATTRIBUTES (NEEDED FOR FUTURE NORMALIZATION) #for attribute in attributeClass: # if attributeClass[attribute]=='continuous': # # TO DO # DISTANCE MEASURE AS A MEAN OF MANHATTAN (continuous) AND SMC (discrete) def dist(obj1, obj2, attributeClass, attributeInfo, targetClass): total=0 n=0 for attribute in attributeClass: if attribute!=targetClass and attributeClass[attribute]=='continuous': # NORMALIZE # TO DO # MANHATTAN DISTANCE # TO DO n+=1 elif attribute!=targetClass and attributeClass[attribute]=='discrete': # SIMPLE MATCHING COEFFICIENT # TO DO n+=1 return float(total)/n # PERFORM CLASSIFICATION def classify(neighbors): counts = {} for n in neighbors: if n['class'] not in counts: counts[ n['class'] ] = 1 else: counts[ n['class'] ] += 1 return sorted(counts, key=counts.get, reverse=True)[0] # ITERATE OVER SAMPLE TO CLASSIFY with open(opt['sample']) as f: samples = csv.DictReader(f, delimiter='\t') # APPEND prediction FIELD FOR OUTPUT ON STDOUT fields = samples.fieldnames[:] fields.append('prediction') writer = csv.DictWriter(sys.stdout, fieldnames=fields, delimiter='\t') writer.writeheader() for sample in samples: nearest = [] # ITERATE OVER TRAINING TO KEEP K NEAREST with open(opt['training']) as f: reader = csv.DictReader(f, delimiter='\t') reader.next() # skip attribute type line reader.next() # skip class line for row in reader: d = dist(sample, row, attributeClass, attributeInfo, targetClass) # update prediction (sorted list of nearest neighbors by decreasing distance) if len(nearest) == 0: nearest.append( {'distance': d, 'class': row[ targetClass ] } ) # 1st iteration else: # TO DO sample['prediction'] = classify(nearest) writer.writerow(sample)