


M1 BBS Data Mining TD Classification
From silico.biotoul.fr
Introduction
Afin de mettre en pratique les concepts vus en cours, nous allons nous appuyer sur des jeux de données publiques hébergées par le UC Irvine Machine Learning Repository.
Pour le premier jeu de données intitulé "mushrooms", il s'agit de classer un champignon comme comestible ou non en fonction d'attributs de type catégoriel. Pour le second - italian wines -, il s'agit de prédire le cultivar du cépage en fonction de mesures quantitatives.
Pour cela, nous utiliserons différents environnements :
- KNIME : un logiciel d'analyse qui est en fait un environnement dérivé de la plateforme de développement intégré Eclipse
- R : environnement orienté calcul numérique & statistiques
- python : un langage de programmation afin de voir l'utilisation de bibliothèque de fouille de données ainsi que pour réaliser son propre programme de classification
Environnement de travail
Nous allons utiliser quelques librairies pas toujours présentes dans un environnement par défaut. C'est l'occasion de s'initier à la gestion de différents environnements de développement et/ou d'analyse. Pour cela, nous allons utiliser l'utilitaire conda. Plus d'informtaion sur cet utilitaire sur silico Conda ou sur gitlab via un projet dans lequel vous pouvez contribuer (envoyer un mail à R. Barriot avec votre identifiant gitlab, ex: @rbarriot pour R. Barriot).
Les commandes suivantes sont à exécuter dans un terminal (surtout PAS en tant qu'administrateur/root).
# dépôts des librairies et programmes conda config --add channels conda-forge conda config --add channels bioconda # création d'un nouvel environnement contenant les librairies spécifiées conda create -n fouille r-base r-tidyverse r-ggally r-reticulate r-rmysql bioconductor-made4 r-codetools r-caTools r-rprojroot r-shiny r-plotly r-knitr r-dt r-kableextra r-cluster r-gridextra r-caret r-e1071 python numpy pandas scipy scikit-learn matplotlib plotly ipykernel nb_conda_kernels jupyterlab auto-sklearn # activation de ce nouvel environnement conda deactivate && conda activate fouille
Classification
TP 2h - Mushrooms - R + Knime - Decision trees + random forests & cross-validation & performances
Les données
Le premier jeu de données concerne des champignons. Il est publié à l'adresse : http://archive.ics.uci.edu/ml/datasets/Mushroom
La description du jeu de données est aussi accessible ici.
Le jeu de données modifié pour inclure une première ligne contenant les noms des colonnes est disponible là : Media:mushrooms.data.txt.
Analyses préliminaires avec R
Charger le jeu de données et utiliser la commande summary pour vous faire une idée du nombre d'instances de chaque classe, et du nombre de modalité de chaque facteur (attribut/dimension/variable).
Etudiez ensuite la liaison entre chaque variable et la classe. Pour cela, vous pourrez utiliser le test du χ2 d'indépendance. Utilisez également la fonction table (pour générer une table de contingence) pour la combiner avec la fonction plot afin d'explorer visuellement les biais entre chaque attribut et la classe.
Exemple de visualisation :

Ces analyses devrait vous permettre de vous faire une idée sur la pertinence d'un attribut en ce qui concerne l'objectif : classer un champignon comme comestible ou pas.
Quels attributs vous semblent les plus pertinents ?
A partir de là, il semble qu'aucun attribut peut permettre à lui seul de classer un échantillon. Nous allons donc utiliser des méthodes d'apprentissage proposées dans le logiciel KNIME.
Analyses avec KNIME
Pour cette partie, nous allons utiliser l'environnement pour la fouille de données KNIME. C'est un logiciel en Java développé à l'origine par l'université de Constance (Allemagne).
L'installation pour linux consiste à télécharger et désarchiver le contenu d'un fichier au format .tar.gz. Une copie de la dernière version a sûrement été placée sur le PC de l'intervenant : http://pc2
Après extraction, il faudra lancer l'exécutable en ligne de commande qui se trouve dans le nouveau répertoire knime_VERSION/knime.
Construction du modèle
La première étape consiste à charger les données. Dans KNIME, ajoutez un noeud File Reader (section IO pour Input/Output) et configurez-le afin de charger le fichier de données.
Comme premier exercice, ajoutez un noeud Decision Tree Learner (induction d'arbre de décision) et connectez la sortie du File Reader à l'entrée du Decision Tree Learner. Configurez ce dernier pour qu'il cherche à prédire la classe du champignon. Lancez l'éxécution de ces noeuds et visualisez l'arbre de décision inféré. Quelles sont les variables les plus importantes ?
Remarque : A la configuration du noeud Decision Tree Learner, observez les autres paramètres disponibles (mesure de pertinence d'un attribut, élagage).
Effectuez la même chose avec un classificateur bayésien naïf et visualisez le modèle obtenu.
Evaluation des performances
Afin de décider quelle méthode fonctionne le mieux (arbre de décision ou bayésien naïf) pour ce jeu de données et avec quels paramètres (gain ratio ou gini index par exemple), vous allez effectuer des validation croisées.
Pour cela, ajoutez et en configurez un noeud Cross validation (section Meta). Une leave-one-out cross validation (ou LOOCV) sera pour ce TP trop couteuse en temps (> 8000 modèles inférés par méthode). Essayez par exemple avec les valeurs 3 et 10 pour le noeud X-partitioner (3-fold ou 10-fold cross validation). Ceci aura pour effet de diviser le jeu de données en entrées en jeux de données d'apprentissage (pour le learner) et jeux de données tests (pour le modèle produit par le learner). Configurez enfin le noeud X-agregator qui confrontera la classe prédite à la classe connue.
Examinez ensuite le taux d'erreurs à l'aide d'un noeud Statistics view.
Faites varier la méthode et ces paramètres et notez à chaque fois les performances obtenues (taux d'erreurs) :
- arbre de décision
- gain ratio ou gini index
- no pruning ou MDL TP1 g2 2017
- bayésien naïf TP1 g1 2017
Qu'observez vous lorsque vous augmentez le nombre de validations croisées (3-fold vs. 10-fold) ?
FIN TP1 2h
Saisie des résultats : https://docs.google.com/spreadsheets/d/1-jodQc1frwTepwzwAvTD7qi_zMwPsj5LfKI6B4qAJKE/edit?usp=sharing
TP 4h - Italian wines - R/tidyverse + LDA
Sujet déposé sur gitlab → https://gitlab.com/rbarriot/datamining/-/tree/master/tp.italian.wine.lda.tidyverse
TP 4h - Classificateur bayésien naïf - jupyterlab + pandas + script
Sujet déposé sur GitLab → https://gitlab.com/rbarriot/datamining/-/tree/master/tp.naive.bayes.jupyter-lab.pandas.script
TP 2h - Classificateur k plus proches voisins - modules python sklearn et auto-sklearn
Sujet sur le dépôt GitLab → https://gitlab.com/rbarriot/datamining/-/tree/master/tp.knn.jupyter.sklearn.autosklearn
Mushrooms - TP 4h - python + pandas - Naive Bayes
Vous allez maintenant programmer un classificateur bayésien naïf en python (sans l'aide d'une librairie).

Etapes pour la construction et l'utilisation d'un classificateur bayésien naïf :
- Lecture du jeu d'apprentissage pour construire la table de probabilité. Utilisation
- des fréquences pour les variables discrètes
- d'une gaussienne pour les variables continues
- Lecture des échantillons à classer
- calcul de la vraisemblance de chaque classe
- attribution de la classe la plus vraisemblable
Le jeu de données mushrooms étant essentiellement constitué de variables discrètes, la tâche sera plus rapide.
La table de probabilité devrait contenir :
- classe EDIBLE : effectifs
- classe POISONOUS : effectifs
- classe EDIBLE, attribut cap-surface : effectifs BELL, effectifs CONICAL, effectifs CONVEX, effectifs FLAT, effectifs KNOBBED, effectifs SUNKEN
- classe POISONOUS, attribut cap-surface : effectifs BELL, effectifs CONICAL, effectifs CONVEX, effectifs FLAT, effectifs KNOBBED, effectifs SUNKEN
- classe EDIBLE, attribut cap-shape : effectifs FIBROUS, ...
- ...
Ceci se représente très bien avec un dictionnaire de dictionnaires de dictionnaires : occurrences[ classe ] [ attribut ] [ modalité ] = effectifs
Ecrire un script python qui scanne un jeu de données d'apprentissage et affiche la table d’occurrences (le modèle). Ce script devrait utiliser la librairie argparse afin d'utiliser les paramètres de la ligne de commande (comme le script knn.py précédemment).
Jeu de données d'apprentissage : Media:Mushrooms.training.data.txt
TP5 g2 2017
Ecrire une fonction attribuant la classe la plus probable d'un individu à l'aide du théorème de Bayes.
Rappel : 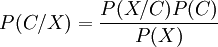
Evaluez les performances avec le jeu de test fourni et comparez avec les résultats obtenus avec KNIME.
TP6 g2 2017
Jeu de données de test : Media:Mushrooms.test.data.txt
TP5 g1 2017
En considérant la classe EDIBLE comme positive et la classe POISONOUS comme négative, calculez :
- sensibilité = VP/P
- spécificité = VN/N
- Précision = VPP = VP/PP
- FDR = 1 - VPP = FP/PP
- VPN = VN/PN
- Exactitude = (VP+VN)/(P+N)
- Taux d'erreurs = 1 - Exactitude = (FP+FN)/(P+N)
Résultats attendus
Tests: 2806 , Errors: 8 , Error rate: 0.29 % prediction/reality | P 1535 | N 1271 P 1529 | TP 1528 | FP 1 N 1277 | FN 7 | TN 1270 Sensitivity TP/P = 0.995439739414 Specificity TN/N = 0.999213217939 Precision TP/PP = 0.999345977763 Accuracy (TP+TN) / (P+N) = 0.9971489665
TP6 g1 2017
Début du script
#!/usr/bin/env python import argparse import csv import numpy as np import scipy.stats import sys from pprint import pprint import pandas as pd # SCRIPT PARAMETERS parser = argparse.ArgumentParser(description='Naive Bayesian learner and classifier.') parser.add_argument('--training', required=True, help='CSV File with a header row in containing training examples.') parser.add_argument('--test', required=False, help='CSV File with a header row containing new objects to be classified for performance evaluation.') parser.add_argument('--sample', required=False, help='CSV File with a header row containing new objects to be classified. NOT YET IMPLEMENTED') parser.add_argument('--model', nargs='?', const=True, help='Only displays the probability table.') parser.add_argument('--gauss', nargs='?', const=True, help='Data is numeric, thus, gaussian should be used to compute probabilities.') parser.add_argument('--delimiter', required=False, default=',', help='Field delimiter in CSV files.') opt = parser.parse_args()
Italian wines
Adaptez le script précédent pour classer les vins italiens (données numériques continues).
Votre script acceptera en paramètre une option supplémentaire :
parser.add_argument('--gauss', nargs='?', const=True, help='Data is numeric, thus, gaussian should be used to compute probabilities.')
Vous pourrez vous aider de la partie stats de la librairie scipy :
import scipy.stats
dont notamment la loi normale et sa fonction de densité https://docs.scipy.org/doc/scipy-0.18.1/reference/generated/scipy.stats.norm.html#scipy.stats.norm
Quelles performances obtenez-vous ? FIN TP5&6 2h
Clustering
Italian wines - TP 4h - clustering
Objectfis : Mise en oeuvre des concepts vus en cours concernant l'évaluation des résultats d'un clustering.
Etapes :
- Sous R, normaliser le jeu de données wine (centrage et réduction)
- Réaliser une mise à l'échelle multi-dimensionnelle pour visualiser les différents résultats que nous obtiendrons ensuite. Pour cela, calculer la matrice de distance puis faire la mise à l'échelle avec la fonction cmdscale. Afficher le plot en faisant apparaître les classes connues.
- Réaliser un clustering (cf. fonction kmeans et ses paramètres de la librairie stats) et afficher le résultat comme précédemment mais en faisant en plus apparaître les clusters.
- Evaluation non supervisée : Calcul du coefficient de silhouette (pour chaque objet et pour le clustering)
- Utilisation du coefficient de silhouette pour déterminer le nombre de clusters (paramètre k de k-means)
- Evaluation supervisée : Calcul de la pureté et de l'entropie, et leur utilisation pour déterminer k
- Comparaison de clustering : utiliser le coefficient simple d'appariement et l'indice de Jaccard pour comparer k-means aux classes réelles.
Rappels :
Coefficient de silhouette :
- ai : distance moyenne de l'objet i aux objets de son cluster
- bi : minimum des moyennes des distances de l'objet i aux objets des autres clusters
-
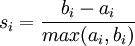

Pureté :
pi = maxj(pij) en d'autres termes, la fréquence de la classe majoritaire dans le cluster i
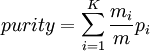 avec K le nombre de clusters, pi la pureté du cluster i, m le nombre d'objets et mi la taille du cluster i.
avec K le nombre de clusters, pi la pureté du cluster i, m le nombre d'objets et mi la taille du cluster i.
Entropie :
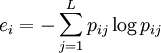 avec L le nombre de classes et pij = mij / mi la probabilité qu'un membre du cluster i appartienne à la classe j
avec L le nombre de classes et pij = mij / mi la probabilité qu'un membre du cluster i appartienne à la classe j
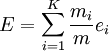 avec K le nombre de clusters et j les classes
avec K le nombre de clusters et j les classes
Precision : fraction d’un cluster j correspondant à des objets d’une classe spécifiée i
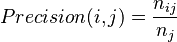
Recall : propension d’un cluster j à contenir tous les objets d’une classe spécifiée i
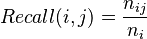
F measure :
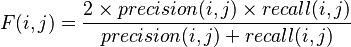
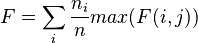
FIN TP7&8 2h