


TD5 Bioanalyse
From silico.biotoul.fr
(→EXERCICE 1 : caractérisation d'une protéine) |
(→EXERCICE 4 : alignement multiple et signature) |
||
| (91 intermediate revisions not shown) | |||
| Line 1: | Line 1: | ||
==EXERCICE 1 : caractérisation d'une protéine== | ==EXERCICE 1 : caractérisation d'une protéine== | ||
| - | A partir de la protéine suivante, faites une recherche de domaine sur | + | A partir de la protéine suivante, faites une recherche de domaine sur [https://www.ebi.ac.uk/interpro/search/sequence-search InterProScan] : |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| + | >NP_060575.1| THAP domain-containing protein 1 isoform 1 [Homo sapiens] | ||
| + | MVQSCSAYGCKNRYDKDKPVSFHKFPLTRPSLCKEWEAAVRRKNFKPTKYSSICSEHFTPDCFKRECNNK | ||
| + | LLKENAVPTIFLCTEPHDKKEDLLEPQEQLPPPPLPPPVSQVDAAIGLLMPPLQTPVNLSVFCDHNYTVE | ||
| + | DTMHQRKRIHQLEQQVEKLRKKLKTAQQRCRRQERQLEKLKEVVHFQKEKDDVSERGYVILPNDYFEIVE | ||
| + | VPA | ||
Vous devez trouver un domaine C2CH-type, nommé THAP : | Vous devez trouver un domaine C2CH-type, nommé THAP : | ||
| - | + | *Quelles sont les positions du domaine selon les banques ? | |
| - | + | *Regardez le domaine dans PFAM et le Logo (en allant sur Signature) et comparez-le à celui de PROSITE (cliquez sur le lien vers External links, puis Logo dans Cross-References) | |
| + | <!-- | ||
| + | A partir de l'alignement Clustal (format Fasta) des séquences de PS50950, générer un logo sur [https://weblogo.berkeley.edu/logo.cgi WebLogo] (Size per Line : 40 x 5 cm) | ||
| + | --> | ||
| + | Pourquoi sont-ils si différents ? | ||
==EXERCICE 2 : recherche d'homologues== | ==EXERCICE 2 : recherche d'homologues== | ||
| - | A partir de la séquence précédente, lancer un BLASTP au NCBI contre la banque SwissProt | + | A partir de la séquence précédente, lancer un BLASTP au [https://www.ncbi.nlm.nih.gov/ NCBI] contre la banque SwissProt, '''en changeant Expect threshold (E-value) à 10''' (algorithm parameters) |
| - | Regardez les résultats : sur quelle partie trouvez-vous des séquences alignées ? | + | *Regardez les résultats : sur quelle partie trouvez-vous des séquences alignées ? |
| - | En fait la famille des protéines THAP contient différents paralogues chez chaque espèce (appelés de THAP 1 à THAP 11) qui n'ont en commun que le domaine THAP situé en position N-terminale. Il y a par contre une très bonne conservation entre orthologues (THAP 1 chez l'homme, souris, zebrafish par exemple) | + | |
| + | En fait, la famille des protéines THAP contient différents paralogues chez chaque espèce (appelés de THAP 1 à THAP 11) qui n'ont en commun que le domaine THAP situé en position N-terminale. Il y a par contre une très bonne conservation entre orthologues (THAP 1 chez l'homme, souris, zebrafish par exemple) | ||
| + | |||
| + | *Passer par l'onglet Taxonomy (en haut de la page) et récupérer les séquences de Primates, au format FASTA (cliquer sur le chiffre (15) à côté du premier mot primates >> Fasta text) | ||
| + | Vous devez avoir 15 séquences. | ||
| + | Copiez-collez ces séquences dans un éditeur de texte et renommez-les pour que le nom apparaisse juste après le signe '>'. Exemple : >THAP1_HUMAN. Attention 2 séquences ne doivent pas porter le meme nom ! | ||
| - | |||
==EXERCICE 3 : recherche dans les banques par mots-clés== | ==EXERCICE 3 : recherche dans les banques par mots-clés== | ||
| - | + | Sur le site du [https://www.ncbi.nlm.nih.gov/ NCBI], cherchez les protéines THAP de souris, poulet et zebrafish, dans la banque RefSeq. (vous chercherez 'THAP*' dans [Title]). <br> | |
| + | Parmi les résultats que vous avez, beaucoup de séquences sont des ''RefSeq models'' (numéro d'accession en XP_). Elles sont le résultat de prédiction automatique avec gnomon (ouvrez une des fiches de séquences pour le vérifier, en regardant la partie 'COMMENT'). Faites une requête pour les supprimer. | ||
| + | Vous devez avoir moins de 17 séquences. | ||
| - | + | Sélectionner les séquences qui ne sont pas des "isoform 2". | |
| - | + | *Pour vous assurer que ces séquences possèdent bien un domaine THAP, cliquez sur Identify Conserved Domains with CD-search, à droite, : que constatez-vous ? les séquences ont-elles toutes un domaine THAP ? | |
| - | + | *Choisissez un programme de [http://www.bioinformatics.nl/emboss-explorer/ EMBOSS] pour comparer les protéines THAP 4 souris et zebrafish : qu'en concluez-vous quant à l'annotation de la protéine de zebrafish ? | |
| - | ==EXERCICE 4 : alignement multiple== | + | *Récupérez les séquences (possédant un domaine THAP) au format FASTA. Mettez-les dans l'éditeur de texte et renommez-les, avec la même nomenclature qu'à l'exercice 2. Attention 2 séquences ne doivent pas porter le meme nom ! |
| - | A partir de l'ensemble des séquences que vous avez récupéré (exercice 2 + exercice 3) | + | |
| + | ==EXERCICE 4 : alignement multiple et signature== | ||
| + | A partir de l'ensemble des séquences que vous avez récupéré (exercice 2 + exercice 3): | ||
| + | |||
| + | *Faites un alignement multiple avec [http://www.ebi.ac.uk/Tools/msa/mafft/ MAFFT] à l'EBI. | ||
En regardant cet alignement, vous devez retrouver la signature suivante : | En regardant cet alignement, vous devez retrouver la signature suivante : | ||
| - | M-x(3, | + | M-x(3,5)-C-x(4)-C-x(9,15)-[FL]-x(2)-[FL]-P-x(8,9)-W |
| + | |||
| + | *Essayez de construire une signature PROSITE (pattern) sur la fin du domaine THAP | ||
| - | + | *Regardez sur quelles séquences de SwissProt sont retrouvées ces 2 signatures (vous pouvez écrire 2 signatures, séparées par "and" (en minuscules)) avec [http://prosite.expasy.org/scanprosite/ ScanProsite] (option 2, décochez la case "Include isoforms"). | |
| - | + | *Calculez la spécificité et la sensibilité de votre signature. | |
| + | Voir le cours [http://snp.toulouse.inra.fr/~mathe/L3/TP5/Sn_Sp.png ici] pour le calcul | ||
| + | ==Annexes== | ||
| + | [http://snp.toulouse.inra.fr/~mathe/L3/TP5/TP5_sequences_distanciel.fasta Les séquences] | ||
| + | <!--MODIF DISTANCIEL 2020 | ||
| + | [http://snp.toulouse.inra.fr/~mathe/L3/TP5/sequences.fasta Les séquences] | ||
| + | --> | ||
| + | Résultat de [http://snp.toulouse.inra.fr/~mathe/L3/TP5/InterProScan_old.htm InterProScan] | ||
| - | + | Résultat de [http://snp.toulouse.inra.fr/~mathe/L3/TP5/Multiple_Sequence_AlignmentEMBL-EBI.html MView] | |
| - | Résultat de ScanProsite | + | Résultat de [http://snp.toulouse.inra.fr/~mathe/L3/TP5/ScanProsite.htm ScanProsite] |
Current revision as of 09:55, 20 December 2022
Contents |
EXERCICE 1 : caractérisation d'une protéine
A partir de la protéine suivante, faites une recherche de domaine sur InterProScan :
>NP_060575.1| THAP domain-containing protein 1 isoform 1 [Homo sapiens] MVQSCSAYGCKNRYDKDKPVSFHKFPLTRPSLCKEWEAAVRRKNFKPTKYSSICSEHFTPDCFKRECNNK LLKENAVPTIFLCTEPHDKKEDLLEPQEQLPPPPLPPPVSQVDAAIGLLMPPLQTPVNLSVFCDHNYTVE DTMHQRKRIHQLEQQVEKLRKKLKTAQQRCRRQERQLEKLKEVVHFQKEKDDVSERGYVILPNDYFEIVE VPA
Vous devez trouver un domaine C2CH-type, nommé THAP :
- Quelles sont les positions du domaine selon les banques ?
- Regardez le domaine dans PFAM et le Logo (en allant sur Signature) et comparez-le à celui de PROSITE (cliquez sur le lien vers External links, puis Logo dans Cross-References)
Pourquoi sont-ils si différents ?
EXERCICE 2 : recherche d'homologues
A partir de la séquence précédente, lancer un BLASTP au NCBI contre la banque SwissProt, en changeant Expect threshold (E-value) à 10 (algorithm parameters)
- Regardez les résultats : sur quelle partie trouvez-vous des séquences alignées ?
En fait, la famille des protéines THAP contient différents paralogues chez chaque espèce (appelés de THAP 1 à THAP 11) qui n'ont en commun que le domaine THAP situé en position N-terminale. Il y a par contre une très bonne conservation entre orthologues (THAP 1 chez l'homme, souris, zebrafish par exemple)
- Passer par l'onglet Taxonomy (en haut de la page) et récupérer les séquences de Primates, au format FASTA (cliquer sur le chiffre (15) à côté du premier mot primates >> Fasta text)
Vous devez avoir 15 séquences. Copiez-collez ces séquences dans un éditeur de texte et renommez-les pour que le nom apparaisse juste après le signe '>'. Exemple : >THAP1_HUMAN. Attention 2 séquences ne doivent pas porter le meme nom !
EXERCICE 3 : recherche dans les banques par mots-clés
Sur le site du NCBI, cherchez les protéines THAP de souris, poulet et zebrafish, dans la banque RefSeq. (vous chercherez 'THAP*' dans [Title]).
Parmi les résultats que vous avez, beaucoup de séquences sont des RefSeq models (numéro d'accession en XP_). Elles sont le résultat de prédiction automatique avec gnomon (ouvrez une des fiches de séquences pour le vérifier, en regardant la partie 'COMMENT'). Faites une requête pour les supprimer.
Vous devez avoir moins de 17 séquences.
Sélectionner les séquences qui ne sont pas des "isoform 2".
- Pour vous assurer que ces séquences possèdent bien un domaine THAP, cliquez sur Identify Conserved Domains with CD-search, à droite, : que constatez-vous ? les séquences ont-elles toutes un domaine THAP ?
- Choisissez un programme de EMBOSS pour comparer les protéines THAP 4 souris et zebrafish : qu'en concluez-vous quant à l'annotation de la protéine de zebrafish ?
- Récupérez les séquences (possédant un domaine THAP) au format FASTA. Mettez-les dans l'éditeur de texte et renommez-les, avec la même nomenclature qu'à l'exercice 2. Attention 2 séquences ne doivent pas porter le meme nom !
EXERCICE 4 : alignement multiple et signature
A partir de l'ensemble des séquences que vous avez récupéré (exercice 2 + exercice 3):
- Faites un alignement multiple avec MAFFT à l'EBI.
En regardant cet alignement, vous devez retrouver la signature suivante : M-x(3,5)-C-x(4)-C-x(9,15)-[FL]-x(2)-[FL]-P-x(8,9)-W
- Essayez de construire une signature PROSITE (pattern) sur la fin du domaine THAP
- Regardez sur quelles séquences de SwissProt sont retrouvées ces 2 signatures (vous pouvez écrire 2 signatures, séparées par "and" (en minuscules)) avec ScanProsite (option 2, décochez la case "Include isoforms").
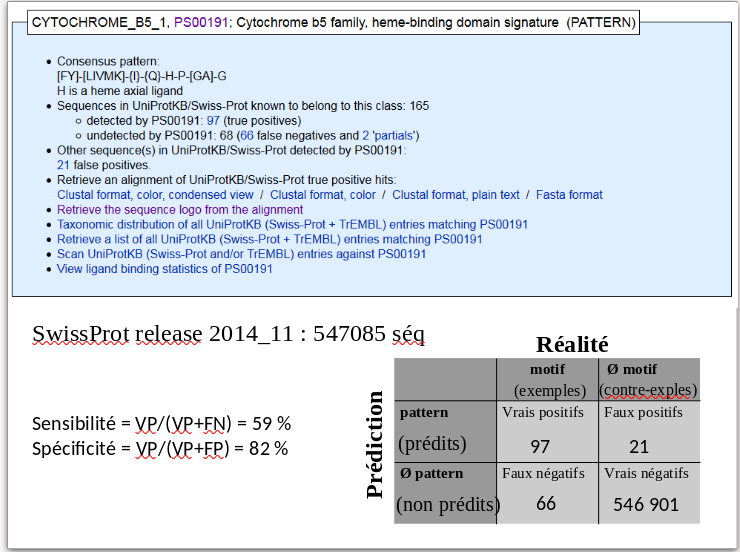
- Calculez la spécificité et la sensibilité de votre signature.
Voir le cours ici pour le calcul
{kind=link}
Annexes
Résultat de InterProScan
Résultat de MView
Résultat de ScanProsite